Blog
| [ « Newer ] | [ View: List | Cloud | Calendar | Latest comments | Photo albums ] | [ Older » ] |
| Google's on crack! | 2007-06-10 10:25:45 |
Ridiculous. I thought suing Microsoft for bundling IE was pretty dumb, but this beats that hands-down. Claiming that this is unfair is at about the same level as antivirus vendors complaining that Microsoft is being anti-competitive by making their OS more secure against virii. *sigh*
[ 2 Comments... ]
| Google Gears and Cloud Computing | 2007-05-31 16:09:05 |
And now, for Google Gears (this post dedicated to gteather :)). First, I find the name "Google Gears" kind of fishy. It seems like a un-intuitive name for something that enables apps to work offline. I suspect it'll be expanded to do more than just that at some point. But that's just random speculation.
Gears seems to finally bring the runaway push-everything-out-to-the-web train back to the station. By using the local machine as a cache for data that resides out in the cloud, Google is fixing the one major flaw with its services - they depend on a reliable Internet connection. By doing this, Google has effectively arrived (in a roundabout but backwards-compatible way) to what I think is the ideal computing state of today.
I'm going to go on a bit of a tangent and describe what I think today's ideal computing state is. Here goes: all user data is stored in a cloud (by "cloud" I don't necessarily mean the Internet - it might also be, for instance, a network file server within some enterprise, or a home file server for a home network). By being stored in a cloud, it can be accessed by any computing device the user chooses to use - whether it's a desktop, laptop, palmtop, tabletop, cellphone, embedded device, kiosk or anything else.
Given that people are already having huge issues syncing their calendar and address books across all of their devices, having a central repository of user data in a cloud is absolutely essential. Also note, by "data" I mean not just calendar entries, but email, documents, media, application preferences - anything that is specific to the user. The data will have to be stored in a standardized format, so that rich clients will also be able to use them. Finally, the cloud has built-in version control. Obviously, this allows the user to retrieve older versions of documents, but also simplifies the process of modifying the data from many devices simultaneously (i.e. collaboration), since file locking and version control is something that we've known how to do well for a long time.
The final advantage to storing data in the cloud - and this is what really makes it worthwhile for the average home user - is transparent backup. By storing data centrally in a cloud managed by professional data-storage people, backups can be made against accidental loss and corruption. No more "Oops, I accidentally deleted my 20 gigs of email!" This is also useful in enterprise situations, where the sysadmins will control the cloud for the enterprise, and can ensure that all system-critical data is properly backed up.
As for applications that the user uses to manipulate the data: one of two things will happen. In the case of cheap-bandwidth devices (desktops, etc.) applications will be cached and run on the devices, but will be originally obtained from master application repositories also stored in the cloud. Updating the application is done by the OS automatically and seamlessly whenever a new version is released. This allows bugfixes and enhancements to propagate trivially. Every time you fire up an app, if you have a connection to the cloud, it will download and install the latest version before running it. If you already have the latest version, or if you don't have a connection to the cloud, it'll just use the version you already have.
The main concern most people have when it comes to self-updating applications is that the new version may be buggy and/or corrupt existing data files. This wouldn't be a problem because of the afore-mentioned version control on data. Even with version control, enterprises may object to self-updating applications because buggy versions may cause loss in productivity. This is also not a problem, because an enterprise would have control over their own cloud and application repository, and can update their application repository only when they are satisfied the new version is solid.
For the case of expensive-bandwidth devices (i.e. cellphones, which may be used on a roaming network in a country with a government monopoly on cell traffic), there will be rich applications that come built-in and need to updated only occasionally. These will cache data more aggressively to minimize bandwidth cost, but still, the data stored in the cloud is the master copy.
Side note: Keep in mind that this ideal state is a function of how people interact with computers. The current trend seems to be tending towards high mobility (people are constantly on the move) and device-independence (people have lots of computing devices), which makes the data-in-a-cloud part of it pretty essential. This wasn't always the case, which is why the ideal state of computing before was very different (personal computing as opposed to cloud computing).
Google has been inching closer to this state for a while. They store data in a cloud. Some of it is already version-controlled. It is backed up and safe from accidental loss (all your data is stored safely on GFS boxes). It can be accessed by anything with a browser, which includes just about any computing device worth using these days. Applications are also stored in the cloud (in the form of huge chunks of Javascript) and are automatically updated (your browser re-fetches any changes every time you access the apps).
There are still a number of things Google needs to do to finish up, and Gears is one of them. One of the implicit requirements in my ideal-state description above is a persistent connection to the cloud. This is where Gears fits in - it allows you to cache both data and applications offline, and transparently handles propagating changes to and from the cloud. This removes the need for a persistent connection to the cloud (which, as much as we want it, is probably not going to be guaranteeable for a while). The fact that Google is going to push the Gears API to become standardized and help browser vendors build it into their browsers also says a lot - they are serious about backing this project.
After looking it all over, Google is most definitely the closest company to the ideal state. There are a handful of things I can think of that they still need to do, almost all of it falls into the "cleanup" category. One of the main things is to allow users to have more control over their own data. Allowing enterprises/businesses to host their own data and application servers would be huge. Currently, Google Apps can be used by enterprises, but all the hardware and software is hosted by Google. This is going to scare away a lot of customers, who would rather have total control over their own data.
This leads directly into the prediction section of this big long post. In my crystal ball, I see...
Once Google has a few more apps (they've already bought Tonic Systems to round out their office suite), they're going to do some polishing and integrating. For instance, they'll provide access to user data in standardized file formats (e.g. making your Google Docs files available in ODF or UOF). Shortly after that's done, I expect them to roll out a site-license option for Google Apps. Enterprises (or other interested parties) will be able to license the Google Apps software suite (complete with email, IM, and office tools) and run their own cloud on their intranet.
In the long term, this, more than anything else, will be what pushes Linux into the mainstream. With no need for Microsoft Office and Outlook/Exchange, a lot of enterprises will be able to ditch Windows altogether and switch to Linux. People who start using Linux at work will then be more open to using it at home. (Dell will probably be in a prime position to take advantage of this, since they've already got a head start on selling pre-built Linux boxes, and will have trained support teams ready to deal with the inevitable deluge of confused users.) Of course, a lot of enterprises will still need Windows for other applications, and they'll probably start using Windows and Office Live, which by then, like most Microsoft products, will be nothing more than a pale shadow of Google Apps.
Oh, and where's Apple in all of this? In your living room. Or rather, your media room. You'll have one, won't you?
[ 3 Comments... ]
| Milan | 2007-05-31 12:23:23 |
A bunch of things have happened recently in the software world. Some of it is noteworthy, and some of it isn't really. The two main announcements both came within the last couple of days: Microsoft Surface Computing (aka "Milan") and Google Gears.
First, Milan. Bill Gates demoed something like this when he came to give a talk at UW a couple of years ago, and I thought it was pretty cool then. There's a bunch of videos on the web of the new desk, and it looks even cooler. However, I say "looks" because I have my doubts about how cool it's actually going to be. I can think of only a handful of really useful applications for this sort of thing - while it is fun to play with digital images and toss them as if they were real, I doubt many people are going to be willing to cough up $10K to do so.
Microsoft on it's own is not going to be able to come up with nearly enough useful applications to make Milan worthwhile - their only hope is to provide a solid API and let people program their own desks. I would assume that they're going to open it up to third-party developers, but it's the usability of the API that's going to make or break this project. They may be the one of the first to demo something like this (they're not the first - see Perceptive Pixel), but I bet lots of companies are already gearing up to embrace and extend the technology. About the same time OLED displays start approaching a reasonable size/cost ratio, the market is going to explode with Milan clones that are way better - imagine a flexible display that you can carry around your house (communicates wirelessly to the base computer somewhere) with all the features and more shown in the Milan demos.
So for now, the ball is in Microsoft's court. For once, they seem to be actually pushing forward with an original product that is somewhat innovative, so it'll be interesting to see how this turns out. I'll cover Google Gears in my next post...
[ 3 Comments... ]
| Development UIs | 2007-05-21 19:54:18 |
I was reading this article on Popfly, and the screenshot of Popfly's UI reminded me of Swordfish. You know, the scene where Hugh Jackman writes his worm hydra on the multi-display machine by coercing the floating blue cubes to fit together.
Although I think traditional software development (i.e. software created by programmers who do software development as a full-time job) isn't likely to move out of the text-based IDE paradigm anytime soon, it's kind of interesting to see how the IDEs for user-developed software are changing. IDEs for this kind of software have to be much easier to use in order to gain any acceptance at all, almost by definition. Look for more of these Hollywood-esque IDEs coming in the near future as companies build more frameworks and allow users to put together their own custom applications.
[ 0 Comments... ]
| Cyberwar | 2007-05-14 12:48:23 |
It appears as though war has evolved to the next level: the Internet. Estonia was attacked with massive DDoS attacks, which took down a number of government websites. Although they blame Russia, it's going to be pretty hard to prove that conclusively because DDoS attacks are inherently geographically distributed over a range of attackers. There may have been hosts in Russia that were part of the attack, but it's hard to tell if that's where the attack originated, or if those hosts were just part of a botnet controlled by somebody in some other country.
Seeing as how botnets can be hired to take down just about any website, it seems that evil villains with nefarious plots to take over the world are going to have a pretty easy time starting wars (or at least cyberwars). On the one hand, taking down a chunk of the Internet could be considered an act of war, since it basically boils down to destruction of a civilian (and possibly military) communication network. On the other hand, it's practically impossible to single out any one country as the source of the attack. It could just be a 10-year old kid in his parents' basement. Unless internet security is beefed up in a hurry, this problem could snowball out of control really fast.
[ 2 Comments... ]
| Copyright and such | 2007-05-09 00:44:29 |
Thanks to Freedom to Tinker, I am now the owner of the 128-bit integer F48F2E8D723EA0​CDCF53A02960E3​1450 (in hex). Anybody using this number WILL be prosecuted. If the AACS can do it, so can I. mwaHAHAHAHA. :)
On a related note, I read Michael Crichton's Next yesterday. Like State of Fear, it seemed entirely too preachy for my liking. While State of Fear was about climate change, Next is about genetics - gene transplants and copyrighting of genes are a couple of the topics he manages to weave into something approaching a story.
I suppose that, in the long run, it's a good thing that he's using his popularity to bring some very important topics into public discussion. However, I do wish he'd do it a little more discreetly - sacrificing the integrity of the novel to make a point leaves me wanting to forget the issue, rather than wanting to learn more about it.
[ 3 Comments... ]
| Reinventing the wheel | 2007-05-05 14:04:37 |
People generally seem to think that reinventing the wheel is a bad thing. Although it can be bad sometimes, there are a lot of cases where it's much better to start from scratch and if necessary, reinvent the wheel. The problem with reusing the wheel is the same as with a lot of things: hidden assumptions. The person who invented the wheel designed it with a certain set of assumptions that weren't documented. Any time you attempt to reuse the wheel, it is quite possible that one or more of these assumptions won't hold, and so reusing the wheel is inefficient at best, and just plain wrong at worst.
One of the assumptions with the wheel, for instance, is that it will be used on a flat surface. If you use a wheel when going up an incline, it requires additional machinery (brakes) to prevent it from rolling back down. If you were to design a car that only went uphill, and you decided to reuse the wheel, you'd have to add a braking mechanism to go with it. On the other hand, if you decided to reinvent the wheel, you might end up with something that looked more like this:
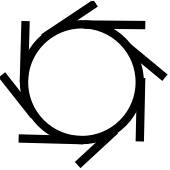
The things sticking out of the wheel would allow it to roll forward (towards the left in the picture above), and would prevent it from rolling backwards. No brakes required (assuming the wheel is strong enough to hold the weight of whatever it's carrying, etc.). Clearly, this solution is more efficient than having to add a complicated and unnecessary braking mechanism.
The same principle applies whenever the choice of reuse vs. reinvent comes up. More often than not, reinventing an item will be more efficient for the overall design, because the item will be redesigned while taking into account the specific context it will be used in. In software, this problem seems to come up over and over. The Ariane 5 disaster was a result of precisely this problem - code from the Ariane 4 was reused, and one of the assumptions (upper bound on acceleration) was no longer valid, resulting in a system failure.
If every system available for reuse were to document every single assumption about the context it expected to be used in, this probably wouldn't be too much of a problem. Although possible in theory, I'm pretty sure this is impossible in practice - most of the time people make assumptions without even being aware they're doing so. One solution is to simply never reuse anything, but that's just as stupid as blindly reusing everything. The correct solution lies somewhere in the middle - reuse whenever possible, but not before going over every explicit and as many implicit assumptions about the system as possible, and making sure that the costs are outweighed by the benefits.
[ 11 Comments... ]
| Freakonomics | 2007-04-19 17:39:40 |
Now that exams are over, I've finally gotten the chance to catch up on my reading - I finished reading Freakonomics the other day, and was somewhat disappointed. Although it was a decent read, I think all the hype I've heard about it kind of ruined it for me. It seemed to be mostly an illustration of the practical benefits of critical thinking - while useful, it was hardly the eye-opening read I was expecting it to be. The sequel seems to be more of the same - a bunch of anecdotes on random topics illustrating how things may not be what they appear. I don't think I'll be diving into that any time soon.
[ 7 Comments... ]
| Froogle, revisited | 2007-04-19 10:50:49 |
As I claimed back in the day, Froogle (now Google Product Search) is starting to grow up, as Google builds it into their next major revenue stream. Last I heard, over 95% of their revenue came from ads. Once Google Product Search is in full swing, look for that number to drop significantly - it won't take long. I'm guessing a couple of years at most before Google is considered a viable contender to Amazon.
[ 0 Comments... ]
| For all the hackers out there.. | 2007-04-18 22:18:16 |
.. some advice worth following.
This brings back a pet peeve of mine when it comes to code cleanliness: people are always afraid to refactor. Refactoring and cleaning code is one of the best things you can do to improve overall readability and maintainability of code, yet so many people prefer to go with the "Don't fix it if it ain't broke" philosophy and just hack around things that may not be optimal.
The thing about code is that most of the time, when it's written, the programmer doesn't know how exactly the code is going to be used. Sure, in a perfect world, we'd have requirements and specifications that would be set in stone and would dictate exactly what the code needs to do, but the world isn't perfect. In 100.000000000% (rounded to 12 significant figures) of cases, code will evolve and change. And the person who writes the code will not be the one who has to change it.
What this means is that more often than not, when you come across some code that doesn't do something in a "clean" way, it's because the person who wrote the code didn't know how you would be using it. Do everybody a favor and fix it properly, rather than just working around it with ugly hacks.
That being said, there are obviously precautions to be taken before refactoring existing code willy-nilly (aside: I seem to be using this phrase a lot more recently). You should make sure that your proposed changes are, in fact, a valid use or extension of the original code. Just because the code does something similar to what you want to do doesn't necessarily mean you should use it; the semantic meaning of what the code does should fit what you're trying to do. Also, if there is other code that depends on the code you're modifying, try to refactor the entire chunk together, rather than hacking up the other depedent code to work around your new refactoring. This may require talking to other people who own the relevant pieces of the code and coordinating changes so that stuff doesn't break.
I've often thought it would be a really cool job to just be "the refactoring guy" for a product at a software company - not assigned to any particular feature/project, but with carte blanche to refactor anybody's code to make it fit better into a cohesive whole. The developer would also be responsible for pulling out libraries across products and code reuse in general. Unfortunately, it would be extremely difficult to set goals or measure the effectiveness of such a role. I think most companies don't have one of these positions explicitly because it's hard to justify paying money to a developer who, strictly speaking, doesn't have to do anything. Instead, one or more developers usually have to step up and take on this role in addition to their usual tasks - and all they get for their trouble is a yelling for meddling in other people's code.
[ 2 Comments... ]
| [ « Newer ] | [ View: List | Cloud | Calendar | Latest comments | Photo albums ] | [ Older » ] |
(c) Kartikaya Gupta, 2004-2025. User comments owned by their respective posters. All rights reserved.
You are accessing this website via IPv4. Consider upgrading to IPv6!